Introducing Vinci KPU
Introduction
On March 14, 2024, at Maisa AI, we announced our AI system to the world, enabling users to build AI/LLM-based solutions without worrying about the inherent issues of these models (such as hallucinations, being up-to-date, or context window constraints) thanks to our innovative architecture known as the Knowledge Processing Unit (KPU).
In addition to user feedback, the benchmarks on which we evaluated our system demonstrated its power, achieving state-of-the-art results in several of them, such as MATH, GSM8k, DROP, and BBH— in some cases, clearly surpassing the top LLMs of the time.
Vinci KPU
Since March, we have been proactively addressing inference-time compute limitations and scalability requirements, paving the way for seamless integration with tools and continuous learning.
Today, we are excited to announce that we have evolved the project we launched in March and are pleased to present the second version of our KPU, known as Vinci KPU.
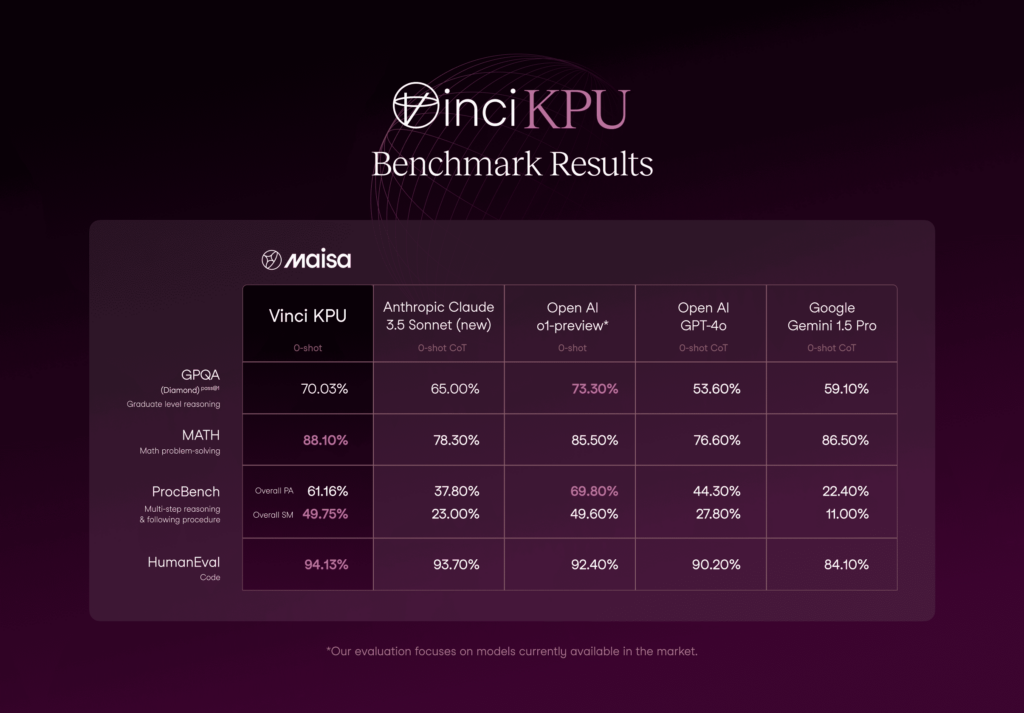
This version matches and even surpasses leading LLMs, such as the new Claude Sonnet 3.5 and OpenAI’s o1, on challenging benchmarks like GPQA Diamond, MATH, HumanEval, and ProcBench.
What’s new on the Vinci KPU (v2)?
Before discussing the updates in v2, let’s do a quick recap of the v1 architecture.
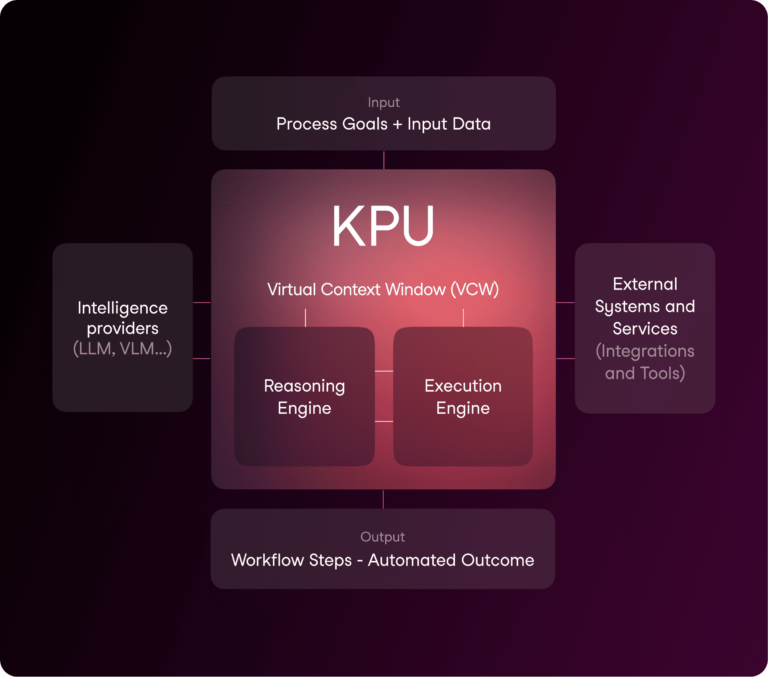
Our architecture consists of three main components: the Reasoning Engine, which orchestrates the system’s problem-solving capabilities; the Execution Engine, which processes and executes instructions; and the Virtual Context Window, which manages information flow and memory.
In this second version, we’ve made significant improvements across all components:
- Reasoning Engine Improvement: We have enhanced the KPU kernel, furthering our commitment to positioning the LLM as the intelligent core of our OS Architecture. This advancement allows for more sophisticated reasoning and better orchestration of system components.
- Execution Engine Enhancements: We have successfully integrated cutting-edge test-time compute techniques and made the execution engine more robust, secure, and scalable. This ensures reliable performance while maintaining high-security standards for tool integration and external connections.
- Virtual Context Window Refinements: We have refined our Virtual Context Window through improved metadata creation and LLM-friendly indexing. This enhancement optimizes how information flows through the system and lays the groundwork for unlimited context and continuous learning capabilities.
KPU Architecture Benefits
What makes these results particularly significant is that they’re achieved by our KPU OS, acting as a reasoning engine, which focuses on understanding the path to solutions rather than providing answers. As main benefits, we can highlight:
- Model Agnostic Architecture (Better base models, better performance)
- Full multi-step traceability:
- configurable observability: Debug mode, visual representation, et.al.
- Provides better human-in-the-loop and over-the-loop control.
- Mitigate, almost fully eliminates, hallucinations:
- While this approach minimizes AI-generated inaccuracies, it may still encounter issues like errors in tool execution, incorrect data sources, or suboptimal approaches to solving the problem.
- Lower Latency to resolve problems than other systems in the market.
- Cost-efficient (up to 40x times cheaper than RAG, reasoning engines and Large Reasoning Models).
- Fully flexible and customizable with out-of-the-box functionalities: Unstructured data management, tools integrations, data processing…
- Autonomous execution with self-recovery/self-healing.
- It is enabled to integrate continuous learning (with VCW) as a module. Providing feedback and incorporating it into the next iteration of the execution.
- Capability to navigate exceptions, sad paths and edge case resolutions autonomously. Setting the foundation to transition from non-deterministic outputs to deterministic execution and output.
Reasoning examples
Where the KPU excels the most is with agentic prompts, as functions to be executed or process to be followed, that require to orchestrate multi-step actions between systems/services out-of-the-box (you don’t need to worry about data management or complex integrations setup). Because it works as an OS Kernel, it does not require to be prompted with Chain of Thought (Think step by step) or complex prompt engineering techniques. Vinci KPU is configured to follow closely instructions and it can easily iterate with feedback if the result is not as expected thanks to its traceability and composition. For example, if you want it to pay more attention to specific words or content, you can put it between asterisk * * and it will pay special focus to it.
Benchmark Analysis
As we mentioned earlier, we have tested our system on some of the most challenging benchmarks at the moment.
Our system has achieved groundbreaking out-of-the-box improvements in first-principle thinking reflected in key benchmarks, particularly in reasoning, procedural tasks and Maths.
GPQA Diamond
Highest quality subset (according to the creators) within GPQA, consisting of 198 questions from the domains of chemistry, physics, and biology.
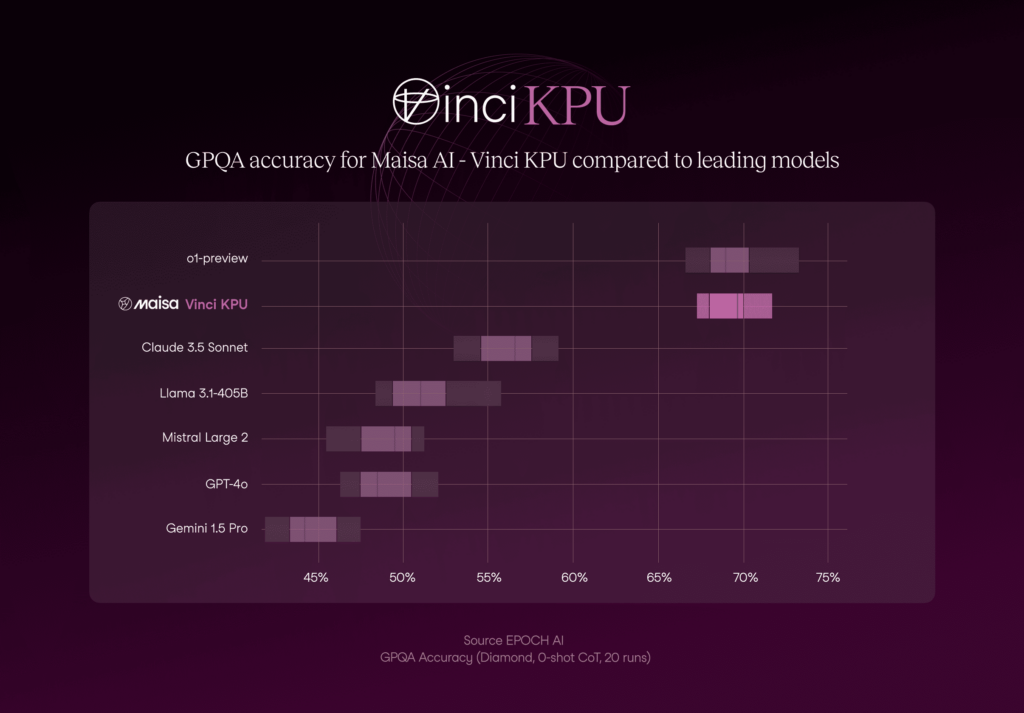
As it can be observed in Figure 1, the KPU v2 performance is the second-best approach with 70.03% accuracy and lower accuracy variability if it is compared with the best option (o1-preview).
Figure 1 also shows the significant differences in the models performance . It looks like two well-discriminated clusters: our approach and o1-preview vs the rest, demonstrating a superior performance compared to the first group.
MATH
The MATH dataset includes problems from math competitions like AMC 10, AMC 12, and AIME, each with a detailed step-by-step solution to help models learn answer derivations. It is challenging, even for experts: computer science PhD students scored around 40%, while a three-time IMO gold medalist scored 90%.
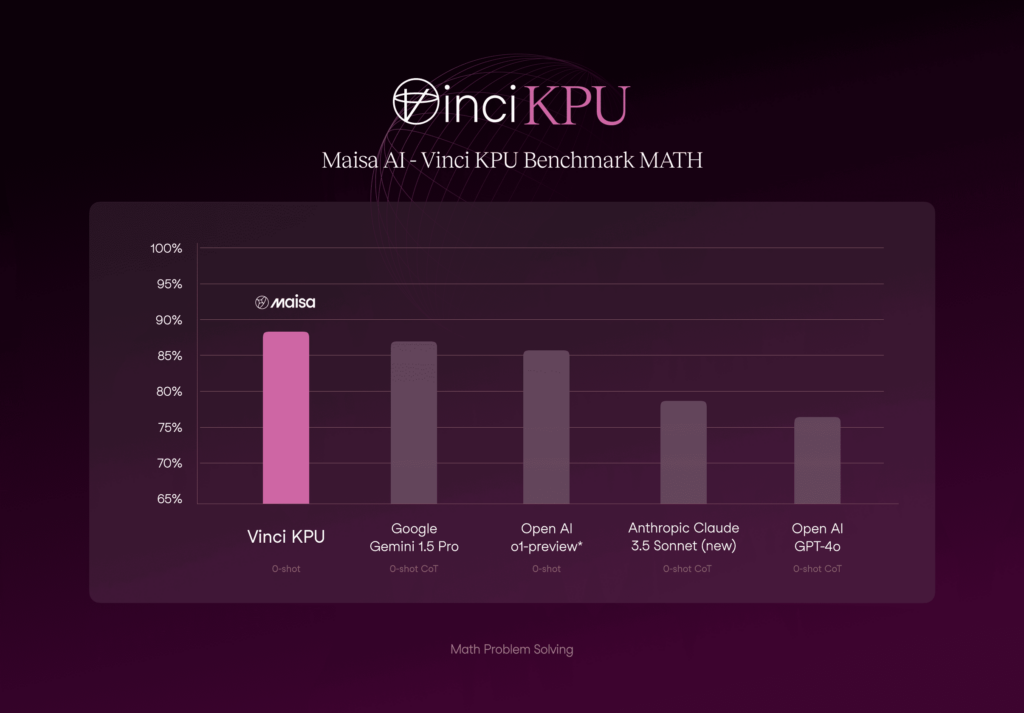
As we can see in the Figure 2, Vinci KPU excels at Maths problems above LLMs.
HumanEval
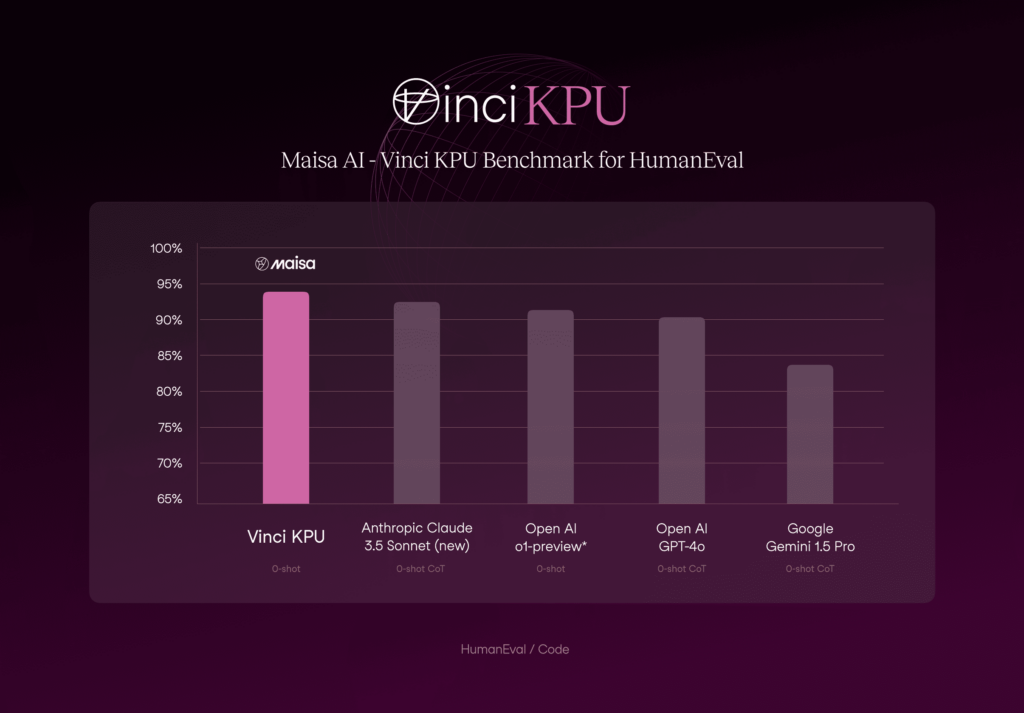
In the presented metrics (figure 3), the KPU v2 surpasses all current state-of-the-art models in the HumanEval dataset. These results position our approach as the leading solution in this domain, which achieved a 94.13 % accuracy.
ProcBench
ProcBench is a benchmark dataset for testing LLMs’ instruction followability. The models are asked to solve simple but long step-by-step tasks by precisely following the provided instructions. Each step is a simple manipulation of either a string, a list of strings, or an integer number. There are 23 types of tasks in total (see reference for more details). The tasks are designed to require only minimal implicit knowledge, such as a basic understanding of the English language and the ordering of alphabets. While the complexity increases with the number of steps, the tasks can essentially be solved by following the instructions without the need for specialized knowledge. While these tasks are easy for humans regardless of their lengths as long as we can execute each step, LLMs may fail as the number of steps becomes larger.
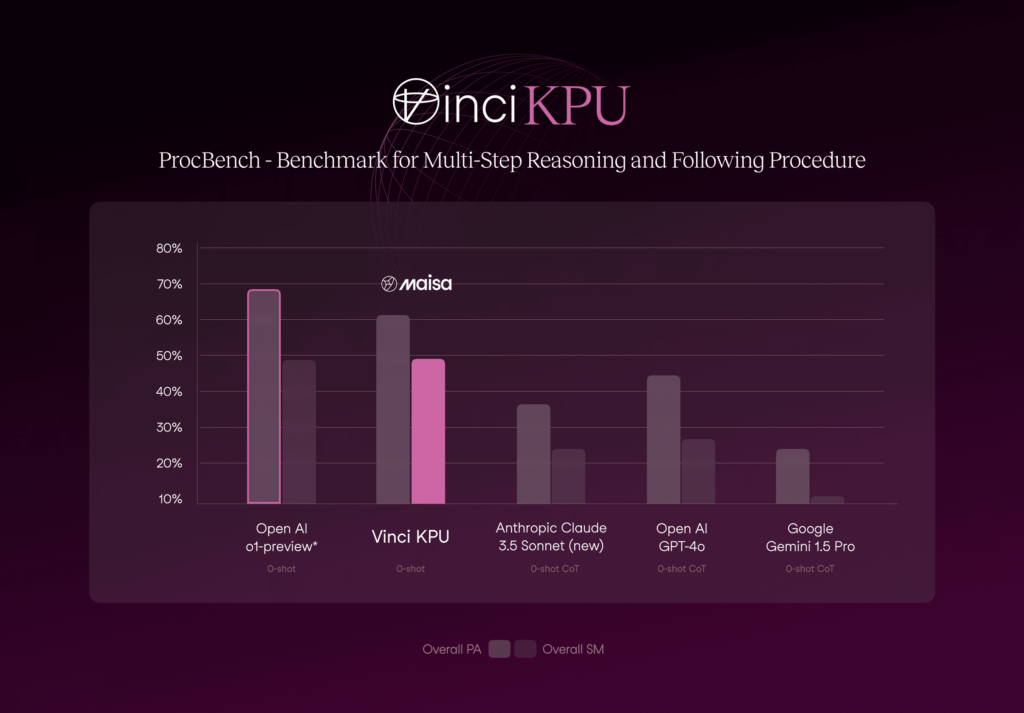
Figure 4. Comparison of Vinci KPU with the state-of-the-art models on ProcBench benchmark.
As Figure 4 shows, numbers obtained with Vinci KPU are on par with the numbers obtained by o1-preview. In terms of Sequential Match (SM), both approaches work similarly (49.75% vs 49.60%, Vinci KPU and o1-preview, respectively) and o1-preview is slightly superior in terms of Prefix Accuracy (PA) (61.16% vs 69.80%, Vinci KPU and o1-preview, respectively).
Our next steps
- Opening public access to our Studio and API.
- Releasing KPU access as Serveless Agentic Functions.
- Rolling out enhanced capabilities over the coming weeks including:
- Advanced tool usage
- Multimodal input/output support
- Customized observability over steps, including Debug mode for developers to iterate faster with visual interpretability features
- Deploying other intelligence providers’ suit of models on production (including O1 as reasoning engine)
- Keep improving the Kernel in two dimensions:
- Make the KPU smarter (still a long way to go).
- Make the KPU faster thanks to dynamic kernel proxying.
The current results are just the beginning. Our model-agnostic system architecture is designed for continuous improvement through self-learning capabilities, ensuring deterministic, reliable, and traceable outcomes.
References
- Rein, D. et al. (2023). GPQA: A Graduate-Level Google-Proof Q&A Benchmark. arXiv preprint arXiv:2311.12022.
- Hendrycks, D. et al. (2021). Measuring Mathematical Problem Solving with the MATH Dataset. arXiv preprint arXiv:2103.03874.
- Chen, M. et al. (2021). Evaluating Large Language Models Trained on Code. arXiv preprint arXiv:2107.03374.
- Fujisawa, I. et al. (2024). ProcBench: Benchmark for Multi-Step Reasoning and Following Procedure. arXiv preprint arXiv:2410.03117.
- Chengshu, L. et al. (2024). Reasoning with a Language Model-Augmented Code Emulator. arXiv preprint arXiv:2312.04474.
- Banerjee, S. et al. (2024). LLMs Will Always Hallucinate, and We Need to Live With This. arXiv preprint arXiv:2409.05746.
- Barkley, L. et al. (2024). Investigating the Role of Prompting and External Tools in Hallucination Rates of Large Language Models. arXiv preprint arXiv:2410.19385.
- Chen, Y. et al. (2024). Steering Large Language Models between Code Execution and Textual Reasoning. arXiv preprint arXiv:2410.03524.
- Siyun Zhao et al. (2024). Retrieval Augmented Generation (RAG) and Beyond: A Comprehensive Survey on How to Make your LLMs use External Data More Wisely. arXiv preprint arXiv:2409.14924.