Escrito por: Maisa Publicado: 14/04/2025

AI can write emails, summarize research, or help you brainstorm ideas. It feels smart and useful. But for any of that to work, the AI needs context—the right information, at the right time, to generate a relevant output.
The context window is the space where the model processes information. It holds the relevant details the user provides—what the model needs to understand and complete a task. Like short-term memory, it’s limited. If too much information is added, parts can be pushed out or forgotten, which affects the quality of the output.
Context windows play a key role in how language models operate, but they come with built-in limits. Like us, these models have a limited attention span. And just like us, when they lose track of key details, their output can go off course. Let’s look at how this works—and why it matters.
Think of a context window like a whiteboard. It’s where the AI writes down what it needs to focus on—a mix of your instructions, the task at hand, and anything it has said before. But space is limited. Once the board is full, something has to be erased to make room for new information.
Technically, the context window is the maximum amount of text the model can process at once. These chunks of text are called tokens. Tokens are chunks of words, and every input or output takes up space. If there’s too much to fit, earlier parts get cut off.
You’ve probably noticed it before without realizing. Maybe ChatGPT forgets part of your request in a long conversation. Or it misses key details when analyzing a document. That’s usually a context limit.
Why does this matter? Because even the smartest AI can’t give good answers without the right context. In business use cases like generating reports, handling customer queries, or reviewing contracts,the model’s output is only as good as what it can see. If the context is incomplete, the results will be too.
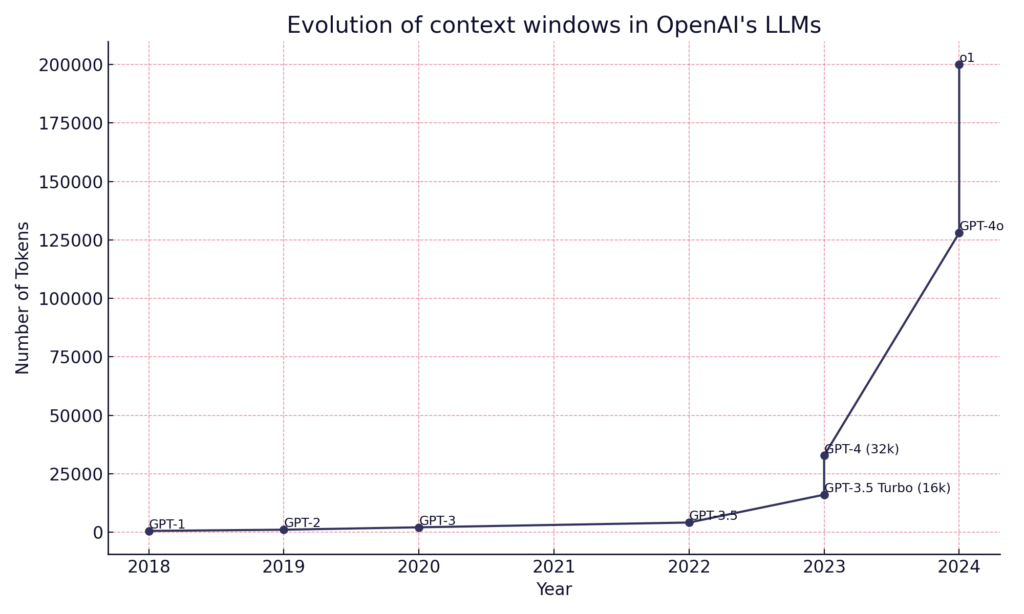
Context windows have grown dramatically. For instance, models like Gemini Pro can handle contexts as large as 2 million tokens—that’s about 5,000 pages of academic content at roughly 300 words per page. With context windows becoming so large, capacity is no longer the main challenge. The real challenge is how these models pay attention.
AI language models use attention mechanisms, which determine what parts of the input to focus on. However, recent research like the paper “Lost in the Middle” shows that these mechanisms have a “U shaped” attention pattern—performance is strongest at the beginning and end of the context window, with a noticeable drop in the middle. This means information located centrally in a large context may be processed less effectively.
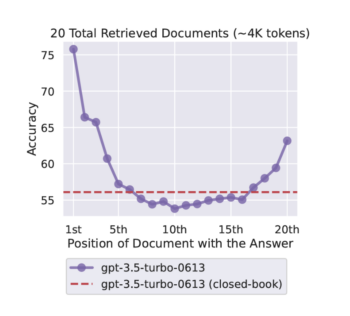
Changing the position of relevant information within an LLM’s input context affects performance in a U-shaped curve. Models perform best when relevant information is placed at the very beginning (primacy bias) or end (recency bias), and their accuracy decreases significantly when important details appear in the middle.
Interestingly, this behavior mirrors human memory patterns known as the serial position effect. Humans naturally exhibit primacy and recency bias, recalling the first and last items more effectively than those in the middle.
So, even with bigger context windows, AI still faces attention challenges. Without complete and accurate context, AI outcomes become less reliable, especially in tasks needing careful reasoning.
Retrieval-Augmented Generation, or RAG, is a method that helps AI overcome context limitations. Simply put, when an AI model doesn’t have enough information, it retrieves additional context from external sources.
When you ask the AI a question or assign it a task, RAG searches external databases or documents for relevant information.
RAG works well for tasks like answering questions from large databases, summarizing lengthy documents, or finding specific content within extensive resources. It keeps AI responses accurate and current, especially when information frequently updates.
However, RAG isn’t without its issues. It inherits the common limitations of AI models, hallucinations. Sometimes the AI retrieves incorrect documents or simply makes up information, resulting in misleading or irrelevant responses.
We’ve observed firsthand that while RAG performs effectively for straightforward tasks like quick database searches, it struggles with complex, multi-step workflows. In agentic scenarios where each step builds upon previous ones, even small retrieval errors compound rapidly. Ultimately, this makes the AI’s final output unreliable or unusable for critical decisions.
Facing these limitations, we take a different approach to managing context and memory in AI systems with our AI Computer, the KPU. Instead of relying solely on large context windows, we computationally manage memory, similar to how a computer uses RAM or cache.
In the KPU, memory module functions as an orchestrator. It selects, processes, and provides the exact information the AI model needs at each step. Without this orchestration, the AI model at its core can miss critical details, leading to unreliable or inaccurate results.
Think of it as giving the AI model precisely the right pages from a book exactly when they’re needed, rather than presenting the entire book at once. This targeted approach ensures our AI has all the necessary context for accurate and dependable performance.
AI models rely heavily on context. Without the right information, even the most advanced systems fail to deliver accurate or relevant results. While context windows have grown significantly and constraints have eased with technological advancements, inherent limitations in the attention mechanisms of AI models still pose critical challenges.
Understanding these limitations is essential. If you’re leveraging AI in your workflows, knowing the boundaries helps you design effective solutions and set realistic expectations.
For us, addressing these limitations involves not just improving models, but also thoughtfully managing context—something we explore with our AI Computer.
Ultimately, awareness of these context constraints isn’t just technical detail; it’s crucial knowledge that shapes how effectively you use AI. By understanding the strengths and weaknesses of your AI systems, you can ensure better outcomes and more reliable performance.