

The architecture behind Maisa is the result of deliberate choices informed by research. A growing body of work has made it clear: while large language models offer impressive generative power, they fall short in several critical areas when used in isolation.
Maisa’s strategic design responds directly to those gaps. Below is an overview of how each component is supported by scientific insight.
Bridging reasoning and execution
📚 ReAct: Synergizing Reasoning and Acting in Language Models
ReAct remains one of the most important foundations in the evolution of agentic AI. It introduced a core loop: reason, act, observe and repeat. This core helped reframe LLMs as active decision-makers rather than passive responders. This concept triggered the shift toward treating AI systems as agents capable of planning, adapting, and executing tasks in dynamic environments. While it’s widely implemented today, its influence remains central to the architecture of AI systems designed for real-world decision-making.
📚 Hallucination is Inevitable: An Innate Limitation of Large Language Models
LLMs are prone to fluent but inaccurate output. This limitation stems from architecture, not data.
📚 Steering LLMs Between Code Execution and Textual Reasoning
📚 Executable Code Actions Elicit Better LLM Agents
📚 Code to Think, Think to Code
📚 Chain of Code: Reasoning with a Language Model-Augmented Code Emulator
These studies confirm the advantage of pairing LLMs with code execution: performance improves through verifiable logic, runtime validation, and structured task decomposition. While visible reasoning chains can appear coherent, they often mask logical gaps. Reliability increases when reasoning is grounded in execution, where each step is tested, not just described.
📚 Chain-of-Thought Reasoning in the Wild Is Not Always Faithful
This paper highlights that exposing reasoning chains through techniques like Chain-of-Thought prompting does not ensure factual accuracy. The presence of a detailed explanation can create a false sense of confidence, even when the underlying logic is flawed or unsupported.
The model may appear to reason more deeply, but the steps often serve as post-hoc rationalizations rather than evidence-based logic. This distinction is critical: coherence doesn’t equal truth. Executable validation remains essential for ensuring that each step reflects actual reasoning.
How this shapes Maisa:
The research outlined in these papers affirms a path we had already taken. Each finding reinforces architectural choices we made early on, confirming that the principles behind Maisa’s design are supported by emerging scientific consensus and designed to operate under real-world enterprise conditions.
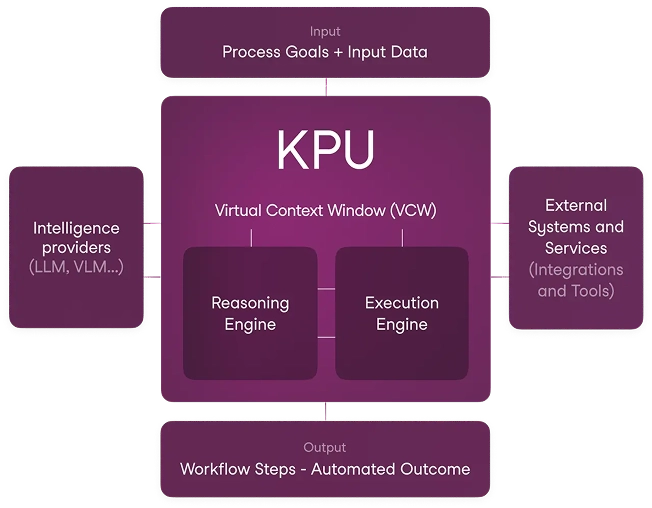
At the core is a reasoning engine structured around iterative decision-making loops, where each action is informed by observation and continuously adjusted until a defined goal is met.
Instead of following fixed instructions, the system adapts continuously as conditions change and new inputs emerge. To support this, Maisa integrates a live code interpreter within the reasoning process, enabling the system to test assumptions, validate outcomes, and apply logical operations as part of its workflow.
Rather than relying on text-based reasoning alone, every step can be executed, verified, and corrected in real time. Code is fundamental, not an add-on. Actions are embedded in executable logic and connected to internal tools, allowing Maisa to interact with APIs, perform data transformations, and drive outcomes based on real results, not generative guesses.
Together, these components make Maisa more resilient, more reliable, traceable, and more capable of handling the dynamic demands of complex enterprise environments.
Beyond the token limit: smarter context management
📚 Lost in the Middle: How Language Models Use Long Contexts
📚 NoLiMa: Long-Context Evaluation Beyond Literal Matching
📚 Michelangelo: Long Context Evaluations Beyond Haystacks
Research shows that LLMs often miss or ignore critical context, especially when it appears mid-sequence or lacks direct phrasing overlap with the query. More context doesn’t guarantee better results.
Retrieval-Augmented Generation (RAG) and beyond
This area of research has become a category of its own, consistently concluding that enabling LLMs to work effectively with proprietary or external knowledge remains an open problem. The most common approaches show clear limitations:
- Fine-tuning often leads to overfitting. The model tends to memorize information and loses general reasoning ability.
- RAG (Retrieval-Augmented Generation) offers a middle-ground solution that works, but leaves significant room for improvement in relevance, structure, and control.
Maisa’s solution:
Our proposed solution is the Virtual Context Window (VCW), a dynamic system designed to index, navigate, and retrieve user-specific data with precision. Acting as an intelligent memory layer, the VCW delivers structured, real-time knowledge to the KPU before reasoning begins. It filters, summarizes, and prioritizes only the most relevant information, reducing token waste, eliminating noise, and maintaining coherence across longer tasks.
This approach allows Maisa to interact with live, domain-specific data efficiently, without the need for retraining or static retrieval strategies.
Built to adapt: iterative refinement and feedback
📚 Self-Refine: Iterative Refinement with Self-Feedback
This research introduces a critical advancement: giving LLMs the ability to evaluate their own outputs and refine them during execution leads to significantly better results. The model is continuously assessing and adjusting its path forward.
Maisa’s approach:
The reasoning engine integrates real-time feedback checkpoints. When an outcome diverges from the intended goal, the system generates an internal review, proposes an alternative, and proceeds with a new iteration. This design supports more resilient behavior across multi-step, high-stakes processes, particularly in enterprise workflows where conditions shift mid-task.
Groundwork for what’s ahead
The direction Maisa has taken is not accidental. It’s the result of mapping architectural choices to known limitations of LLMs, and to emerging techniques that push those limitations further.
Scientific foundations remain central as we continue developing enterprise-grade digital workers capable of reasoning, executing, and adapting in real-world environments.