Today, Maisa is thrilled to announce the KPU (Knowledge Processing Unit). KPU is a proprietary rich framework that leverages the power of LLMs with the decoupling of reasoning and data processing in an open-ended system capable of solving complex tasks.
This white paper aims to show what the KPU is, which is its architectural overview and how it has outperformed more advanced language models, such as GPT-4 or Claude 3 Opus, in several reasoning tasks.
This is our first technical report of our KPU technology. To see the updated version visit our research page
Escrito por: Maisa Publicado: 15/03/2024
In recent periods, the community has observed an almost exponential enhancement in the proficiency of Artificial Intelligence, notably in Large Language Models (LLMs) and Vision-Language Models (VLMs). The application of diverse pre-training methodologies to Transformer-based architectures utilizing extensive and superior quality datasets, followed by meticulous fine-tuning during both Supervised Fine-Tuning (SFT) and Reinforcement Learning from Human Feedback/Reinforcement Learning with Augmented Imitation Feedback (RLHF/RLAIF) stages, has culminated in the development of models. These models not only achieve superior performance metrics across various benchmarks but also provide substantial utility in everyday applications for individuals, encompassing both conversational interfaces and API-driven services.
These language models, based on that architecture, have several innate/inherent problems that persist no matter how much they advance their reasoning capacity or the number of tokens they can work with.
The “Attention” mechanism of the Transformer Architecture has a quadratic spatio-temporal complexity. This implies that as the information sequence we wish to analyze grows, both the processing time and memory demand increase proportionally. Not to mention the problems that arise with this type of model, such as the famous “Lost in the middle“[2] , which means that sometimes the model is unable to retrieve key information if it is “in the middle” within that context.
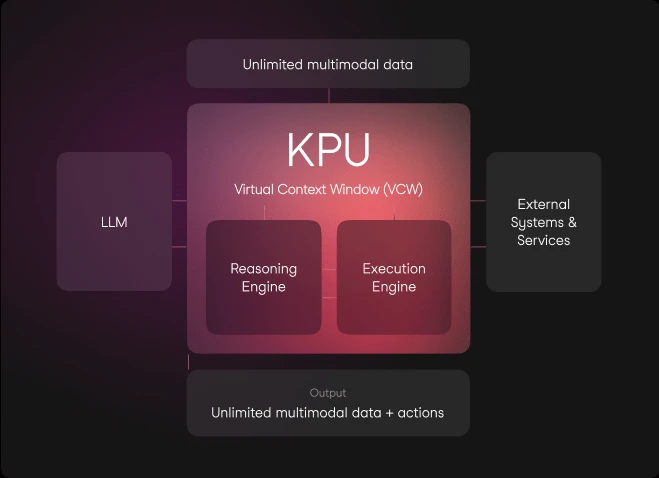
The architecture we have named KPU (Knowledge Processing Unit) has the following main components.
This system has been inspired by the architecture of Operating Systems, where they are responsible for managing and orchestrating the various hardware and firmware components of the computer, presenting an interface oriented to the user’s needs, abstracting the user from the complexity and technical details of the hardware.
This decoupling between reasoning and command execution allows the LLM to focus exclusively on reasoning, relieving it of any vulnerable operation of hallucination, data processing or retrieval of current information.
The articulation of these 3 components, and in general the KPU architecture, opens the door to future analyses of the quality and performance on tasks with large volumes of data and multimodal content, open problem solving, interaction with digital systems (such as apis and databases), and factuality.
We are pleased to show the excellent results we have achieved by testing our system against the reasoning benchmarks on which state-of-the-art LLMs are usually evaluated. As we will see below, we will compare well-known models such as GPT-4, Mistral Large, Claude Opus or Google Gemini against our KPU using as reasoning LLM GPT-4 Turbo itself. We will see how using a Language Model IN the KPU improves the performance of the LLM reasoning.
GSM8k benchmark (Grade School Math 8K) is composed of 8.5 thousand high-quality, linguistically diverse mathematics problems for elementary schools. The benchmark was created to support the task of answering questions on basic mathematical problems that require multi-step reasoning. [paper]
Numerous methodologies have been explored in the context of “experimental setup” including Chain of Thought, few-shot prompting, and Code-based self-verification. We deemed it pertinent to evaluate our system using a zero-shot approach to closely mimic standard operational conditions. Additionally, we refrained from employing any form of prompt engineering or iterative attempts.
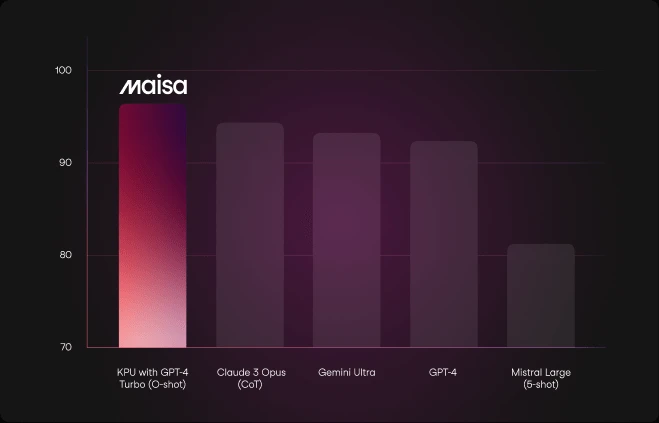
Comparison of KPU with GPT-4 Turbo, Claude 3 Opus, Gemini Ultra, GPT-4 and Mistral Large (pre-trained) on GSM8k (Grade School Math 8k)
In the presented graphics, the KPU surpasses all current state-of-the-art models in the GSM8k test-set. The results position our approach as the leading solution in this domain.
On the other hand, MATH Benchmark is a dataset of 12,500 challenging competition mathematics problems. Each problem in MATH has a full step-by-step solution which can be used to teach models to generate answer derivations and explanations.
In this specific instance, a concise system prompt was employed to elicit responses from the KPU in LaTeX format. This approach facilitates more straightforward cross-validation with the benchmark’s ground truth examples. Contrary to other evaluations involving different models, no alternative configurations were utilized in this context.
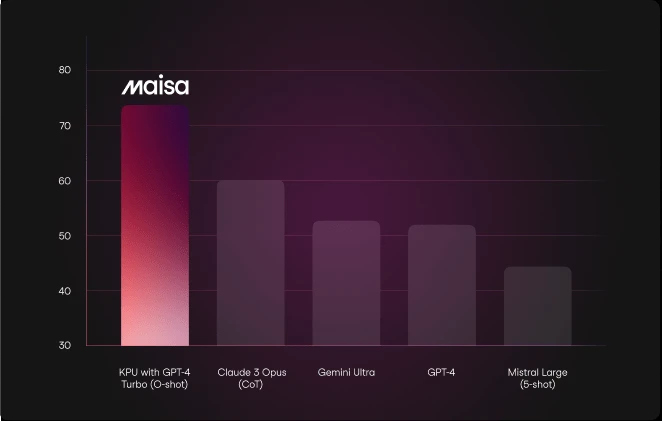
Performance of KPU with GPT-4 Turbo, Claude 3 Opus, Gemini Ultra and GPT-4 and Mistral Large on MATH benchmark.
The performance of the KPU in the specified benchmark significantly surpasses that of other models, a remarkable achievement given the benchmark’s complexity. Notably, state-of-the-art models such as Claude 3 Opus struggle to correctly answer more than 60% of the questions posed by this benchmark. This outcome suggests a paradigm shift, especially considering that this version of the KPU is still in its beta phase. It implies that, for cross-disciplinary questions involving mathematics, the KPU may soon offer a higher degree of reliability than currently achievable with Large Language Models (LLMs).
DROP. It is a 96,000-question benchmark created by crowdsourcing and in an adversarial manner, in which a system must solve references in a question, perhaps to multiple input items, and perform discrete operations on them (such as addition, counting or sorting). These operations require a much more complete understanding of the content of paragraphs than was necessary for previous datasets. [PAPER]
In contrast to the evaluation of models like GPT-4, which utilized a 3-shot approach, the KPU was benchmarked using a zero-shot configuration without the application of any prompt engineering techniques. This approach resulted in the KPU establishing a new state-of-the-art benchmark in performance, showcasing its strong capability of complex reasoning.
BBH. Big Bench Hard is a subset of the Beyond the Imitation Game Benchmark (BIG-bench) that focuses on tasks considered beyond the capabilities of current language models. It consists of 23 challenging tasks selected from the BIG-bench suite, which were chosen because previous evaluations of language models did not exceed the average performance of human raters on these tasks. From the 23 tasks in this benchmark we have chosen 3 subsets that we consider more appropriate for our KPU because they are more focused on multi-step reasoning.
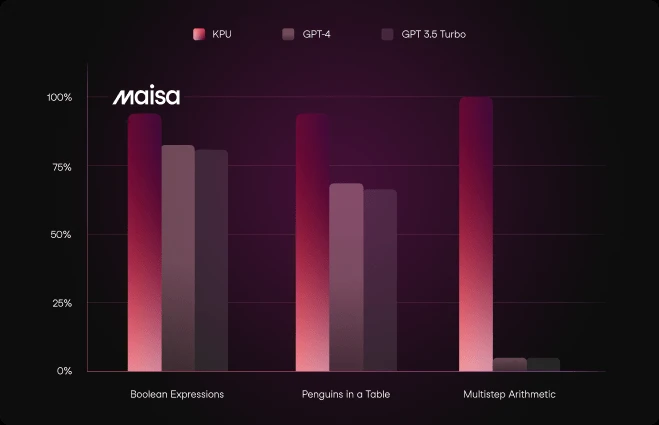
Comparison of KPU with GPT-4 Turbo, Claude 3 Opus, Gemini Ultra and GPT-4 and on DROP (Discrete Reasoning Over Paragraphs) benchmark.
As it can be noted in this chart, reasoning demanding tasks such as Boolean Expressions or Arithmetic are very good responded by the KPU.
The KPU, even in its initial iteration, has outperformed established Language Large Models (LLMs) such as GPT-4, Mistral Large, Claude Opus, and Google Gemini in various reasoning benchmarks. Utilizing GPT-4 Turbo within the KPU significantly boosts its reasoning capabilities. It has set new standards across multiple domains, including elementary math reasoning (GSM8k), advanced competition math problems (MATH Benchmark), complex reading comprehension (DROP), and advanced reasoning challenges (selected tasks from BBH), demonstrating unparalleled performance. These achievements underscore the KPU’s potential to revolutionize complex problem-solving and reasoning in AI, marking a significant milestone in our journey towards developing more sophisticated and capable AI systems.
All the results and methodology used are reproducible here.
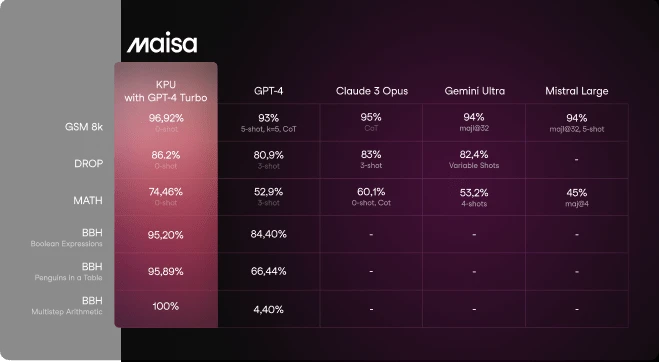
Comparison of KPU with GPT-4 Turbo, Claude 3 Opus, Gemini Ultra, GPT-4 and Mistral Large (pre-trained) on GSM8k (Grade School Math 8K)
Currently in its beta development phase, the KPU is not ready for commercial use just yet. However, with its imminent release on the horizon, we invite you to sign up for our waiting list, which will grant you access to the beta version.
If you have other inquiries or want to learn more about what we are building at Maisa, you can send us an email at contact@maisa.ai or via the contact form.
We have an exciting roadmap ahead and can’t wait to share and make accessible our advancements.
Follow us on X to be updated with the latest news: @maisaai_