Escrito por: Maisa Publicado: 26/11/2024
On March 14, 2024, at Maisa AI, we announced our AI system to the world, enabling users to build AI/LLM-based solutions without worrying about the inherent issues of these models (such as hallucinations, being up-to-date, or context window constraints) thanks to our innovative architecture known as the Knowledge Processing Unit (KPU).
In addition to user feedback, the benchmarks on which we evaluated our system demonstrated its power, achieving state-of-the-art results in several of them, such as MATH, GSM8k, DROP, and BBH— in some cases, clearly surpassing the top LLMs of the time.
Since March, we have been proactively addressing inference-time compute limitations and scalability requirements, paving the way for seamless integration with tools and continuous learning.
Today, we are excited to announce that we have evolved the project we launched in March and are pleased to present the second version of our KPU, known as Vinci KPU.
This version matches and even surpasses leading LLMs, such as the new Claude Sonnet 3.5 and OpenAI’s o1, on challenging benchmarks like GPQA Diamond, MATH, HumanEval, and ProcBench.
Before discussing the updates in v2, let’s do a quick recap of the v1 architecture.
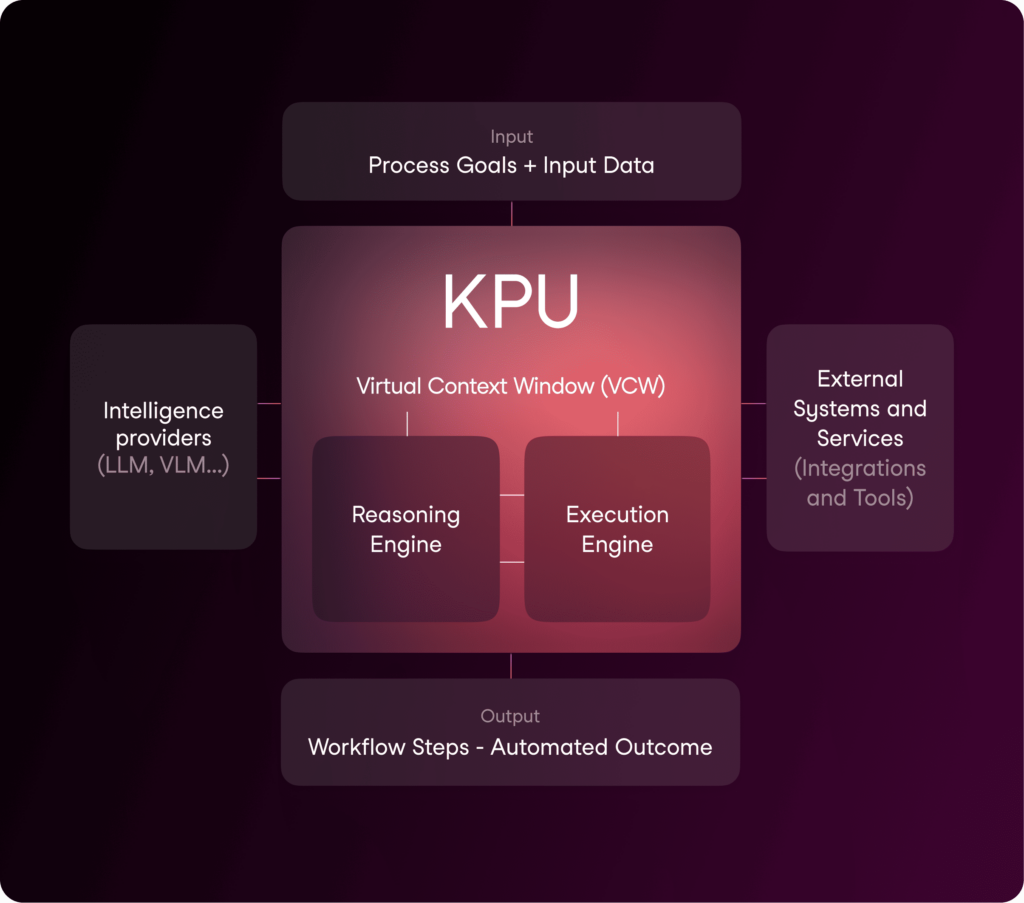
KPU OS Architecture
Our architecture consists of three main components: the Reasoning Engine, which orchestrates the system’s problem-solving capabilities; the Execution Engine, which processes and executes instructions; and the Virtual Context Window, which manages information flow and memory.
In this second version, we’ve made significant improvements across all components:
What makes these results particularly significant is that they’re achieved by our KPU OS, acting as a reasoning engine, which focuses on understanding the path to solutions rather than providing answers. As main benefits, we can highlight:
Where the KPU excels the most is with agentic prompts, as functions to be executed or process to be followed, that require to orchestrate multi-step actions between systems/services out-of-the-box (you don’t need to worry about data management or complex integrations setup). Because it works as an OS Kernel, it does not require to be prompted with Chain of Thought (Think step by step) or complex prompt engineering techniques. Vinci KPU is configured to follow closely instructions and it can easily iterate with feedback if the result is not as expected thanks to its traceability and composition. For example, if you want it to pay more attention to specific words or content, you can put it between asterisk * * and it will pay special focus to it.
Spotify Fun Playlist
Query: Your goal is to create two playlist and return the links. Use the Spotify API and the bearer token i’m sending you. Careful with the calls as they have a lot of extra content:
1. Name the first playlist: Vinci KPU is Magic
2. Add songs to the playlist so that first word of each song title, matches exactly to create the sentence: Anon Can you feel it?
3. Name the second playlist: Approaching kardashev scale
4. Add songs to the playlist so that the first letter of each song title, creates the sentence: I CAN FEEL IT ACCELERATE
5. At the end, return both links so I can click them and open the playlist directly
Attachment: token.txt
Answer: Here are your Spotify playlists:
https://open.spotify.com/playlist/4sgQXqHqX2nSEOEbEsu0V7
https://open.spotify.com/playlist/4bkXxK35m1CYln1ZipdxSH
Spotify-example
Time Taken: 45 seconds
REASONING:
To kick things off, I’m setting up the necessary groundwork to connect with your Spotify account. This involves **establishing a secure connection** using the token you’ve provided. By doing this, I ensure that I have the proper permissions to access and manage your playlists. It’s the first crucial step in moving forward toward creating those unique playlists you requested.
I’m delving into the hiccup identified in the prior attempt to ensure everything is running smoothly. It appears we need to rethink how we’re using the access token provided, transitioning to a more effective method for connecting to the Spotify service. By checking the connection through the current user’s information, I aim to confirm that everything is set up correctly before moving forward with your requests. This step is crucial for establishing a solid foundation on which to build the playlists you asked for.
The journey continues as I work on **crafting your first playlist** titled *”KPU is Magic.”* My focus is to find songs that capture the essence of the phrase **“Anon Can you feel it?”**. To do this, I’m starting by searching for a song that begins with the word **“Anon,”** which is the first piece needed to build your playlist. I’m searching thoroughly to ensure I gather the right songs that fit your vision.
To keep building on our creative playlist, I’m taking a moment to look for songs that start with the word **“Can”**. This step is crucial because each song title must match the words of the phrase ***“Anon Can you feel it?”*** that you want to capture in your playlist. I’m verifying that we find the right match to keep everything in sync with your vision. The previous step helped set the stage by creating the playlist and searching for the first word, **“Anon”**, ensuring we have a solid start.
I’m moving forward with our progress by looking for a song that begins with the word **“It.”** and question mark **?**. This step is crucial because we’re gathering the specific titles needed to form the playlist that corresponds with your request. Each track we discover helps build the desired musical sentence: “Anon Can you feel it?” Based on our previous explorations, I am continuing to search for tracks that perfectly align with the list of phrases you’ve provided.
In this step, I’m diving deeper into creating the second playlist, named “Approaching kardashev scale.” The goal is to find songs that each begin with the letters from the sentence: *I CAN FEEL IT ACCELERATTE*. To kick things off, I’m searching for a song that starts with the letter “I.” This process helps me ensure that I’m gathering the right tracks to fulfill your playlist vision, matching each letter to create a coherent musical experience.
Download HuggingFace Report
Query: Using my huggingface token:<token> please create a .md file listing all the available dataset and all the available models at the organization of https://huggingface.co/<org_id> For each dataset add the title, explanation, comment… so they are contextualized and understood. First section with the model overview + list of all models, including models familiy names and available models. Second section with Datasets overview + list of all of them.
Answer:
1.1 Models Overview
<org_id> offers various language models specialized in Spanish language processing, including:
1.1.2 Model Families
1.1.2.1 Llama Family
[List of models with description]
1.1.2.2 Mistral Family
[List of models with description]
1.1.2.3 Mamba Family
[List of Models with description]
1.2 Datasets Overview
<org_id> maintains various datasets for training and evaluation:
1.2.1 Instruction Tuning Datasets
[List of Dataset with description]
1.2.2 Evaluation Datasets
[List of Dataset with description]
1.2.3 Legal Domain Datasets
[List of Dataset with description]
Time taken: 45 secs
REASONING:
To begin the process of gathering information from the HuggingFace organization, I’m setting the stage by ensuring that I have the necessary access. This involves creating a secure connection with the HuggingFace platform using your provided token. By storing the token in a safe place, I’ll enable myself to seamlessly retrieve important details about the models and datasets you requested. This initial step is essential to lay the groundwork for the comprehensive overview you wish to compile in the markdown file.
To move forward in creating the markdown file, I’m **accessing the list of all available models** from the specified organization. This step is crucial because it allows me to compile a comprehensive overview of the models, ensuring that each one is included with the necessary context. By referencing the earlier setup where I established my access credentials, I’m now ready to collect and present this valuable information.
In this step, I’m taking the collection of models I found earlier and transforming it into a more manageable format. **By converting it into a list, I can easily view and understand the different models available from the organization**. This helps me present the information in a clear way, ensuring that each model is accounted for as I prepare to create your markdown file.
I’m now focusing on **collecting essential information** about the datasets associated with the organization. This will help me create a comprehensive list for you. Given that I’ve already accessed the models overview, this next step will allow us to contextualize the datasets effectively and ensure that they are well understood in the final markdown file.
Matrix Reading
Query: Given this matrix:
C @ T S A F * Q
A T A C Q $ S S
T # S C I C % C
S A T ! Z S Q Q
A C T S S T C #
Z Q C A S T T &
Q S C A A C S Z
F F F F S S C FRead the letters or symbols on the diagonal from the bottom right corner, to the upper left corner, in order from the bottom to the top.
Answer: Reading the diagonal from the bottom right corner to the upper left corner, the sequence of characters is: FSTS!STC
Time Taken: 15 seconds
REASONING:
1. Building the Matrix for Easy Access
In this step, I’m creating a structured format to hold the letters and symbols you provided. This carefully organizes the information into a manageable layout, making it easier for me to find and read the diagonal elements you are interested in. This sets the stage for the next steps where we’ll focus on extracting those specific letters from the bottom right to the top left of the matrix.
2. Extracting the Diagonal Characters
I’m now focused on gathering the characters that lie along the diagonal from the bottom right corner to the top left of the matrix. This step is important because it helps me fulfill your request by carefully selecting the specific letters and symbols you want.
To do this, I’m moving up and to the left, one step at a time, collecting each character as I go. I’ll store these characters in a list and then combine them into a single string for a clear answer.
This follows from the previous step, where I successfully created the matrix. Now it’s time to retrieve the diagonal elements that you specified in your original query.
3.Verifying the Diagonal Characters
I’m cross-checking the previously collected diagonal characters by examining each position individually from the bottom right corner to the top left of the matrix. This is a careful step to ensure that the values we gathered are accurate and represent what we see. I’ve set up a way to list out each matrix position I’m verifying along with the characters at those spots, making sure to provide clarity on what I found at each coordinate. This builds on the results from the last step, where I found the sequence of characters to confirm their correctness.
4.Final Confirmation of the Diagonal Sequence
I’m taking a moment to ensure everything we found aligns perfectly with your request. The sequence we derived earlier has been carefully checked and verified, confirming that we accurately captured the diagonal letters moving from the bottom right corner to the upper left corner of the matrix. The result showcases the characters in their intended order: F, S, T, S, !, S, T, C. This leads us to the clear conclusion, which I’ve succinctly formatted for your understanding: “The diagonal sequence from bottom right to upper left is: FSTS!STC.”
5. Verifying the Diagonal Characters
I’m taking a moment to double-check the letters I gathered from the diagonal of the matrix. Starting from the bottom right corner and moving to the upper left, I’m carefully examining each character by looking at their positions one by one. The verification process involves checking the specific coordinates, ensuring that the letters align with what I found earlier. This step not only confirms my previous result, which was “FSTS!STC,” but also guarantees that every detail is accurately captured. It’s all about ensuring precision in the final outcome, so you can trust the result.
Numbers Logic
Query: Write all the possibilities (in increasing order) for 7 positive numbers, all different from each other, such that their sum is divisible by each of the 7 numbers, and the sum is as small as possible
Answer: There are two possible combinations of 7 different positive numbers where their sum is divisible by each number and the sum is minimal (48): 1. [1, 2, 3, 4, 6, 8, 24] 2. [1, 2, 3, 6, 8, 12, 16] Both combinations sum up to 48, which is the smallest possible sum that satisfies all the requirements. Each number in both combinations divides 48 evenly, and all numbers are different from each other.
Time Taken: 52 seconds
REASONING:
In this step, I’m initiating a detailed exploration of the mathematical challenge at hand. At the core of my efforts, I’m establishing a way to assess if a number can be evenly shared among a group of seven different positive numbers.
To lay the groundwork, I’m first assessing the smallest numbers: 1 through 7, as this gives me a clear starting point with the least total sum. I’m analyzing whether this sum can be evenly divided by each of these numbers, setting the stage for identifying combinations that align with your request.
This careful outlining will help us identify valid options that meet the criteria of being both unique and summing up in such a way that they work seamlessly together.
I’m diving deeper into the mathematical challenge by taking a more organized approach. This involves assessing various combinations of 7 unique positive numbers and determining their sums to see if each sum can be divided evenly by all numbers in the group. This method will reveal which combinations meet the requirements, ensuring I find potential solutions while keeping the sums as low as possible. Drawing from the previous attempt, which yielded no valid combinations, I’m investigating a broader range to improve our chances of success.
In this step, I’m diving deeper into the combinations we’ve identified earlier. The goal here is to carefully evaluate each set of numbers we’ve found and determine their total sum. By doing so, we can identify which combination yields the smallest sum while meeting the conditions set out in your original query. This analysis focuses on ensuring that we’re not just finding valid sets, but also optimizing for the smallest possible sum, which is essential for solving the problem effectively. Let’s see how these combinations stack up against each other!
In this stage, I’m taking a closer look at the first set of numbers we’ve found, which is (1, 2, 3, 6, 8, 12, 16), and its total sum of 48. The goal here is to ensure that this total is compatible with each individual number in the set. To do this, I’m checking if 48 can be evenly divided by each number, which confirms that this combination holds the necessary property for our problem. By validating this, we’re getting closer to finding a suitable solution for your query, ensuring that we’re on the right track before moving forward.
I’ve reached a point where I’ve gathered all the findings related to our search for seven unique positive numbers. This specific combination, (1, 2, 3, 6, 8, 12, 16), adds up to 48, which meets all our criteria: it consists of seven different numbers, and their total is perfectly divisible by each one of them. To ensure that this is indeed the most optimal solution, I’m now putting it to the test against smaller combinations to see if another set could possibly yield a lower sum. This thorough examination is key to confirming our results and ensuring we have the best possible answer for your query.
I’m taking a closer look at a different set of numbers: (1, 2, 3, 4, 6, 8, 12), which seems promising.
The first thing I’m doing is calculating the total sum of these numbers to see how they stack up. I’m also ensuring that each individual number divides this sum without leaving any remainder, which is essential to meet the requirements of your query. This helps confirm if this combination might indeed be a viable option.
This step follows our earlier findings, where the sum of our previous combination was 48. We’re now testing against this new combination to see if it may offer an even smaller sum while still adhering to all conditions.
I’m building on what we’ve already discovered to enhance our search for valid groups of numbers. We previously identified that our first valid solution was (1, 2, 3, 6, 8, 12, 16) with a sum of 48, but a new potential group, (1, 2, 3, 4, 6, 8, 12), was found to be invalid as 36 is not divisible by 8. To ensure we find the best solution, I’m adopting a more rigorous approach to check for divisibility comprehensively. By systematically examining all combinations up to 20, I aim to uncover any additional valid sets while adhering closely to our requirements.
I’m taking a moment to double-check our results, particularly focusing on the combination (1, 2, 3, 6, 8, 12, 16), which had a sum of 48. This sum seems to be optimal, and to ensure that we haven’t overlooked any possibilities, I’m now broadening my search to include a wider range of numbers. The goal is to be absolutely certain that this combination is indeed the best solution, meeting all the criteria of having different numbers whose sum is divisible by each number. This is a crucial step toward confirming the accuracy of our findings!
I’m taking a close look at the latest findings, focusing on two potential combinations of numbers, both with a sum of 48. The goal is to confirm whether these combinations meet the necessary conditions.
I will check each number in both combinations to see if the total is divisible by them, ensuring they adhere to the criteria set out in your query. This is an important step to validate that our solutions not only exist but are also valid and optimal for your requirements. By confirming these details, I’ll be able to assure you that we have the correct set of numbers that fulfill the criteria in the most efficient way possible.
Through this verification process, I’ll present the results for both combinations, allowing us to determine if either—or both—can be considered the solution you need.
In this crucial step, I’m reflecting on the findings we’ve gathered throughout our exploration. We’ve discovered two valid combinations of seven unique positive numbers, both achieving the minimum sum of 48. To align with your request, I’m now arranging these combinations in increasing order to provide a clear and concise answer. This way, you can easily see all the possibilities that meet your criteria. The solutions are being organized for your convenience:
I will ensure you have the clear answers you sought while maintaining the integrity of our findings.
In this step, I’m carefully examining two combinations of numbers that both total to 48 to ensure they meet all the requirements. The numbers in question are (1, 2, 3, 4, 6, 8, 24) and (1, 2, 3, 6, 8, 12, 16). The goal is to confirm that their total is divisible by each individual number in the combinations, serving as a final check to ensure that we have indeed identified valid solutions that fit the criteria of the original problem. Through this analysis, I aim to provide clarity on whether these combinations hold the potential for being the best outcomes.
Hotel and Rooms
Query: A hotel has 100 rooms, numbered from 1 to 100, that have light off if they’re not being used. At 1:00 a.m. 100 guests arrive and occupy all the rooms. The first guest then goes to each room and flips the light switch (on if off, off if on). The second guest goes to each even-numbered room and flips the switch. The third guest goes to each third room and flips the switch. This procedure continues until the 100th guest only turns on room 100. How many rooms have lights on at midnight? A) 10 B) 20 C) 0 D) 50
Answer: The answer is C) 0. At midnight, before the guests arrived at 1:00 a.m., all lights were off in the unused rooms. However, it’s worth noting that after all 100 guests completed their light-switching procedure at 1:00 a.m., exactly 10 rooms had their lights on: rooms 1, 4, 9, 16, 25, 36, 49, 64, 81, and 100.
Time Taken: 18 seconds
REASONING:
1. Initial Setup: Turning on All Lights for the First Guest
In this step, I’m laying the groundwork for solving the problem by simulating the actions of the guests with the lights in the rooms. To kick things off, I start with all the room lights turned off, which reflects their initial state.
As the first guest enters, they go to every room and flip the switch to turn on all the lights. This crucial first action sets the stage for understanding how each subsequent guest will interact with the rooms. The result of this first step indicates that every room’s light is now illuminated, creating a situation where all rooms are occupied and awake at 1:00 a.m.
2. Continuing the Light Flip Dance
I’m tracking the ongoing activity of each guest as they flip the light switches in a specific manner. Building on the initial outcome where all lights were turned on by the first guest, I’m now simulating the actions of guests numbered 2 through 100. Each guest is following a unique pattern based on their number; for instance, the second guest flips the switches in every even-numbered room, the third guest tackles every third room, and so forth.
This process highlights how the light switches change state in a systematic way as each guest sequentially performs their task. Once all the guests have taken their turns, I will tally up how many lights remain on by the end of this entertaining night, putting together the bigger picture of what’s happening with the rooms.
3. Understanding the Result of 10 Rooms with Lights On
To clarify our result of 10 rooms with lights still on, I’m digging a bit deeper into the reasoning behind it. In this step, I’m exploring the relationship between room switches and their factors. A room’s light will remain on if it gets flipped an odd number of times, which occurs only for rooms that correspond to perfect squares. This reflects how each room’s number interacts with its factors. Essentially, I’m identifying those perfect squares up to 100 to confirm that they indeed exhibit this unique behavior, allowing us to understand why lights are on in only 10 of the hotel rooms.
4. Listing Perfect Squares for Confirmation
I’m checking the perfect squares that we have identified previously to ensure they match our earlier findings. This step is important because it helps us confirm our results from the simulation, reinforcing that the rooms with lights on correspond to these specific numbers. By showing the perfect squares, I aim to provide clarity on why exactly 10 rooms have their lights illuminated.
5. Verifying Which Rooms Have Their Lights On
To ensure our findings align with the simulation, I am checking for the specific rooms that have their lights left on. By looking at the results from the previous steps, I’ve established that 10 rooms have their lights illuminated. In this step, I’m simply identifying which of those rooms correspond to that outcome. This helps confirm that we understand the pattern correctly and provides clarity on the situation, as we’re focusing on the rooms where guests’ actions resulted in the lights remaining on.
6. Clarifying a Key Detail in the Query
It’s important to recognize an oversight in the question regarding the timing of events. At midnight, before the guests arrived at 1:00 a.m., all lights were still off in the unused rooms. This makes it clear that the answer to how many lights were on at midnight is 0.
To summarize:
7. Verifying Room Status
I’m taking a closer look at the results of the previous steps to pinpoint exactly which rooms have their lights still on. Based on our earlier findings, I am identifying the specific room numbers corresponding to the lights that remain lit. With the earlier conclusions leading to a total of 10 rooms being lit, I will now specify exactly which of those rooms are shining bright. This will give us a comprehensive understanding of the final outcome—the exact rooms benefiting from the light!
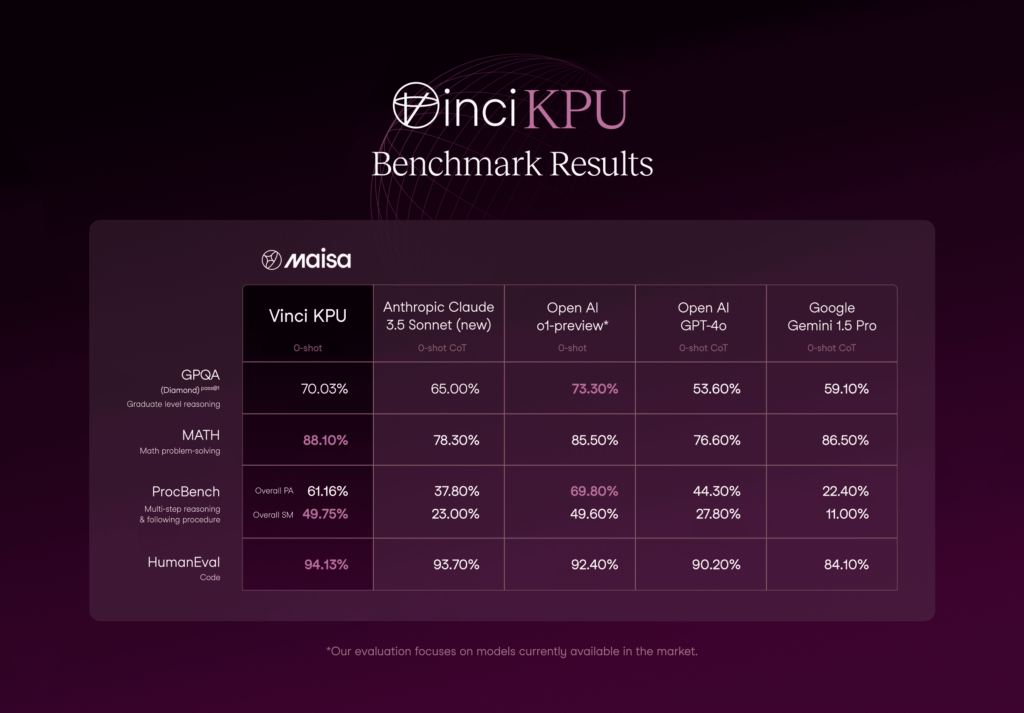
As we mentioned earlier, we have tested our system on some of the most challenging benchmarks at the moment.
Our system has achieved groundbreaking out-of-the-box improvements in first-principle thinking reflected in key benchmarks, particularly in reasoning, procedural tasks and Maths.
GPQA Diamond
Highest quality subset (according to the creators) within GPQA, consisting of 198 questions from the domains of chemistry, physics, and biology.
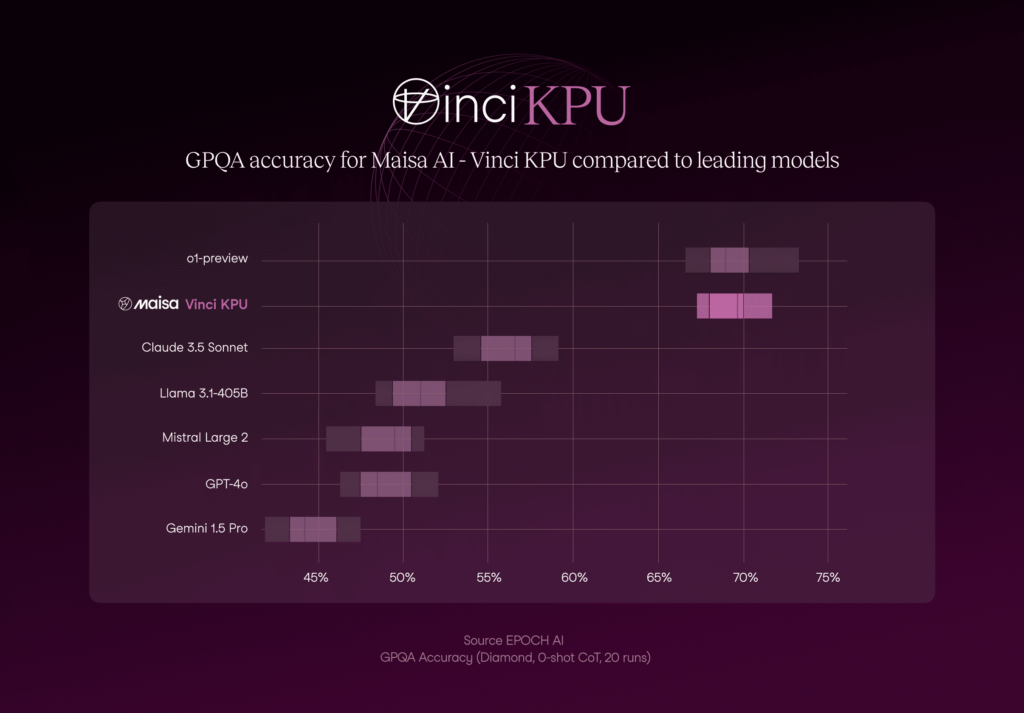
Figure 1. Comparison of Vinci KPU withe the state-of-the-art models on GPQA benchmark.
As it can be observed in Figure 1, the KPU v2 performance is the second-best approach with 70.03% accuracy and lower accuracy variability if it is compared with the best option (o1-preview).
Figure 1 also shows the significant differences in the models performance . It looks like two well-discriminated clusters: our approach and o1-preview vs the rest, demonstrating a superior performance compared to the first group.
MATH
The MATH dataset includes problems from math competitions like AMC 10, AMC 12, and AIME, each with a detailed step-by-step solution to help models learn answer derivations. It is challenging, even for experts: computer science PhD students scored around 40%, while a three-time IMO gold medalist scored 90%.
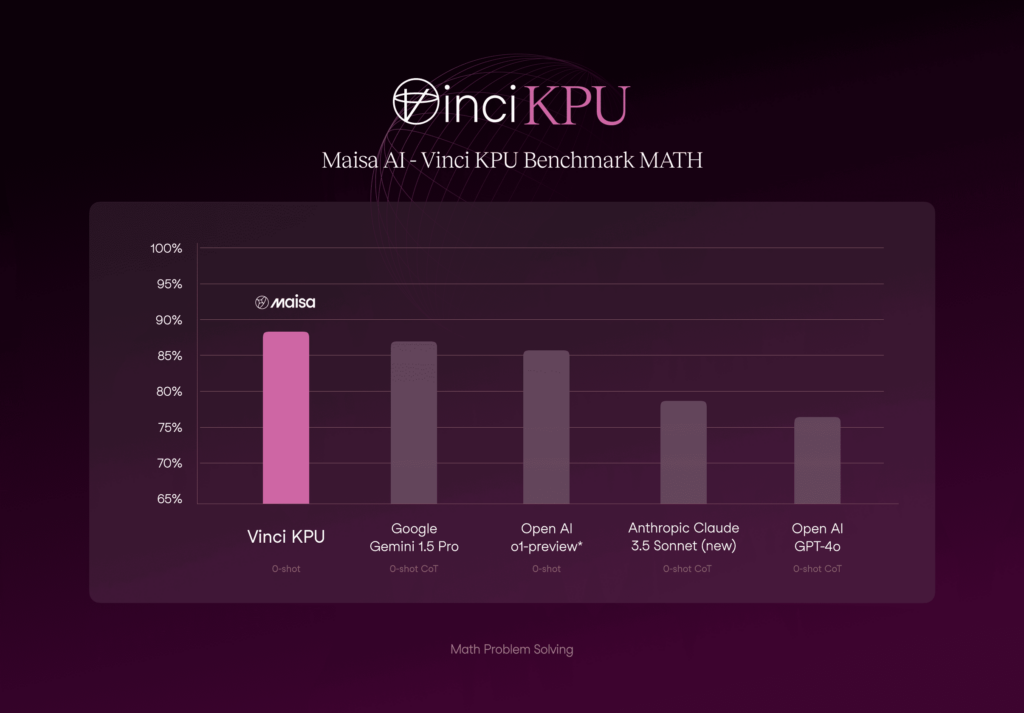
Figure 2. Comparison of Vinci KPU with the state-of-the-art models on MATH benchmark.
As we can see in the Figure 2, Vinci KPU excels at Maths problems above LLMs.
The HumanEval dataset by OpenAI contains 164 handwritten programming problems with function signatures, docstrings, code bodies, and unit tests, designed to assess comprehension, reasoning, algorithms, and basic math skills. It evaluates models’ functional correctness and problem-solving abilities.
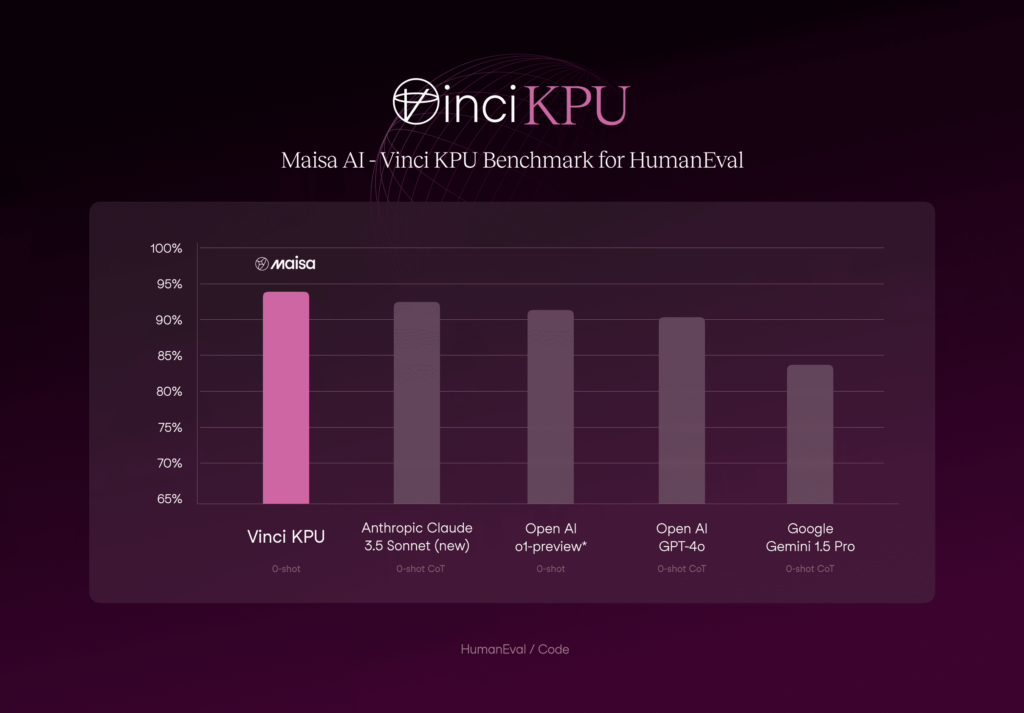
Figure 3. Comparison of Vinci KPU with the state-of-the-art models on Code/programming benchmark.
In the presented metrics (figure 3), the KPU v2 surpasses all current state-of-the-art models in the HumanEval dataset. These results position our approach as the leading solution in this domain, which achieved a 94.13 % accuracy.
ProcBench is a benchmark dataset for testing LLMs’ instruction followability. The models are asked to solve simple but long step-by-step tasks by precisely following the provided instructions. Each step is a simple manipulation of either a string, a list of strings, or an integer number. There are 23 types of tasks in total (see reference for more details). The tasks are designed to require only minimal implicit knowledge, such as a basic understanding of the English language and the ordering of alphabets. While the complexity increases with the number of steps, the tasks can essentially be solved by following the instructions without the need for specialized knowledge. While these tasks are easy for humans regardless of their lengths as long as we can execute each step, LLMs may fail as the number of steps becomes larger.
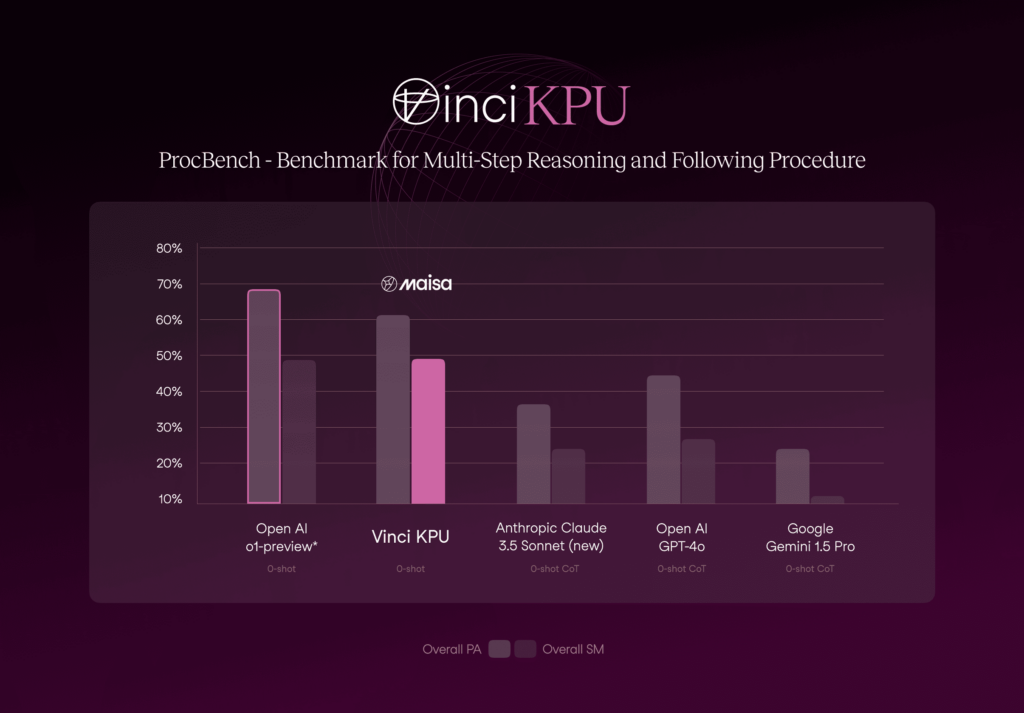
Figure 4. Comparison of Vinci KPU with the state-of-the-art models on ProcBench benchmark.
As Figure 4 shows, numbers obtained with Vinci KPU are on par with the numbers obtained by o1-preview. In terms of Sequential Match (SM), both approaches work similarly (49.75% vs 49.60%, Vinci KPU and o1-preview, respectively) and o1-preview is slightly superior in terms of Prefix Accuracy (PA) (61.16% vs 69.80%, Vinci KPU and o1-preview, respectively).
The current results are just the beginning. Our model-agnostic system architecture is designed for continuous improvement through self-learning capabilities, ensuring deterministic, reliable, and traceable outcomes.