
Hello World
In recent periods, the community has observed an almost exponential enhancement in the proficiency of Artificial Intelligence, notably in Large Language Models (LLMs) and Vision-Language Models (VLMs). The application of diverse pre-training methodologies to Transformer-based architectures utilizing extensive and superior quality datasets, followed by meticulous fine-tuning during both Supervised Fine-Tuning (SFT) and Reinforcement Learning from Human Feedback/Reinforcement Learning with Augmented Imitation Feedback (RLHF/RLAIF) stages, has culminated in the development of models.
These models not only achieve superior performance metrics across various benchmarks but also provide substantial utility in everyday applications for individuals, encompassing both conversational interfaces and API-driven services.
These language models, based on that architecture, have several inherent problems that persist no matter how much they advance their reasoning capacity or the number of tokens they can work with.
- Hallucinations. When a query is given to an LLM, the veracity of the response cannot be 100% guaranteed, no matter how many billions of parameters the model in question has. This is due to the intrinsic token-generating nature of the model, which generates the most likely token, not necessarily a factual one [1].
- Context limit. Lately, more models are appearing that are capable of handling more tokens, but we must wonder: at what cost?
The “Attention” mechanism of the Transformer Architecture has a quadratic spatio-temporal complexity. This implies that as the information sequence we wish to analyze grows, both the processing time and memory demand increase proportionally. Not to mention issues such as the well-known “Lost in the middle” problem [2], where models fail to retrieve key information if it is located in the middle of long contexts.
- Up-to-date. The pre-training phase of an LLM inherently limits the data up to a certain date. This affects the model’s ability to provide current information. Asking about events after its training cutoff may lead to inaccurate responses unless external mechanisms are used.
- Limited capability to interact with the digital world. LLMs are fundamentally language-based systems and cannot natively interact with external services such as APIs, files, or software systems, which limits their ability to solve complex real-world problems.
Architectural Overview
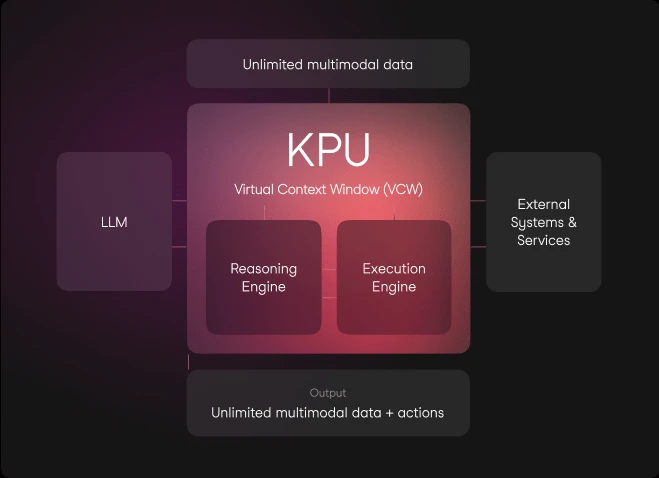
The architecture we have named KPU (Knowledge Processing Unit) has the following main components:
- Reasoning Engine. It is the “brain” of the KPU, orchestrating a step-by-step plan to solve the user’s task. It relies on an LLM or VLM and available tools. The LLM is plug-and-play and has been extensively tested with GPT-4 Turbo.
- Execution Engine. Receives commands from the Reasoning Engine, executes them, and sends the results back as feedback for re-planning.
- Virtual Context Window. Manages the flow of data and information between the Reasoning Engine and Execution Engine. It ensures that reasoning remains within the LLM context while data stays external, maximizing token efficiency. It also integrates external sources such as the internet, Wikipedia, and files.
This system is inspired by Operating Systems, which orchestrate hardware and software components while abstracting complexity for the user.
This decoupling between reasoning and execution allows the LLM to focus exclusively on reasoning, reducing risks related to hallucination, data handling, or outdated information.
The interaction of these components enables advanced capabilities such as large-scale data processing, multimodal reasoning, open problem solving, integration with digital systems (APIs, databases), and improved factual reliability.
Benchmarks
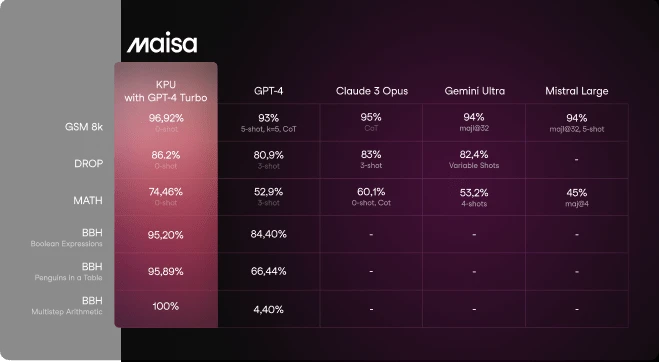
We are pleased to show the excellent results achieved by testing our system against well-known reasoning benchmarks. We compare models such as GPT-4, Mistral Large, Claude Opus, and Google Gemini against our KPU using GPT-4 Turbo as the reasoning model. The results demonstrate how embedding an LLM within the KPU significantly improves reasoning performance.
Setting a new paradigm at Math Reasoning
GSM8k benchmark (Grade School Math 8K) consists of 8,500 high-quality math problems designed to evaluate multi-step reasoning.
We evaluated our system using a zero-shot approach without prompt engineering or iterative attempts, to reflect realistic usage conditions.
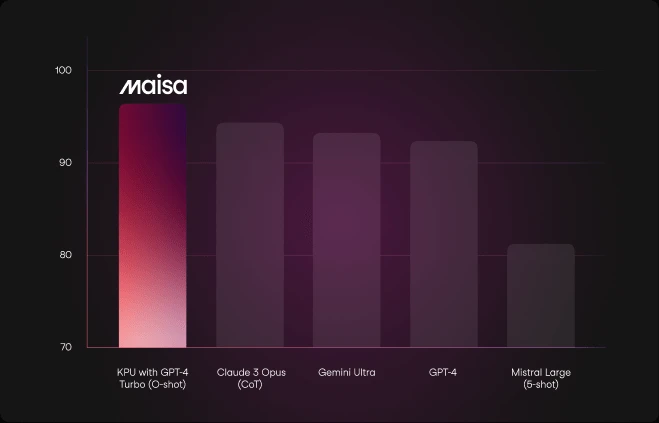
The KPU surpasses all state-of-the-art models in GSM8k, positioning it as a leading solution in mathematical reasoning.
MATH Benchmark includes 12,500 challenging competition-level math problems with step-by-step solutions.
In this evaluation, responses were generated in LaTeX format to facilitate validation. No additional configurations or prompt engineering were used.
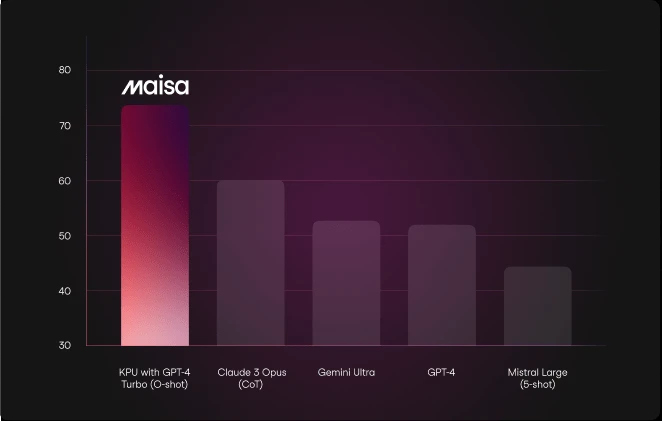
The KPU significantly outperforms other models, marking a potential paradigm shift in mathematical reasoning capabilities.
Boosting reading and discrete comprehension
DROP is a benchmark requiring systems to perform reasoning over paragraphs, including operations like addition, counting, and sorting.
Using a zero-shot configuration without prompt engineering, the KPU establishes a new state-of-the-art result, demonstrating strong complex reasoning capabilities.
Beyond advanced reasoning challenges
BBH (Big Bench Hard) consists of tasks designed to go beyond current model capabilities. We selected subsets focused on multi-step reasoning.
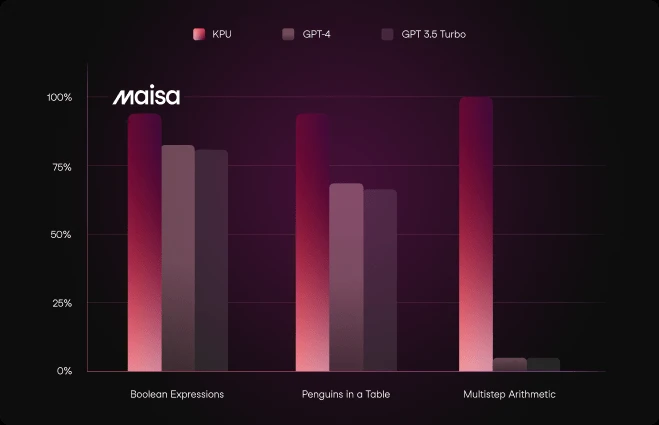
The KPU performs particularly well on tasks requiring logical reasoning such as Boolean expressions and arithmetic.
Summarizing the system’s evaluation
The KPU, even in its initial iteration, has outperformed established LLMs such as GPT-4, Mistral Large, Claude Opus, and Google Gemini across multiple benchmarks.
It sets new standards in:
- Elementary math reasoning (GSM8k)
- Advanced mathematics (MATH)
- Reading comprehension (DROP)
- Complex reasoning tasks (BBH)
These results highlight the KPU’s potential to significantly improve AI reasoning and problem-solving capabilities.
All results and methodology are reproducible here.
KPU Use Availability
Currently in its beta phase, the KPU is not yet ready for commercial use. However, with its release approaching, you can join the waiting list to gain early access.
For inquiries or more information, contact us at contact@maisa.ai or through our contact form.
Follow us on X for updates: @maisaai_
References
- Xu, Ziwei et al. (2024). Hallucination Is Inevitable: An Innate Limitation of Large Language Models.
- Liu, Nelson F. et al. (2023). Lost in the Middle: How Language Models Use Long Contexts.
- Hendrycks, Dan et al. (2021). Measuring Mathematical Problem Solving With the MATH Dataset.
- Dua, Dheeru et al. (2019). DROP: A Reading Comprehension Benchmark Requiring Discrete Reasoning Over Paragraphs.
- Suzgun, Mirac et al. (2022). Challenging BIG-Bench Tasks and Whether Chain-of-Thought Can Solve Them.